Enhancing Diabetes Prediction through Ensemble Machine Learning Models on Survey-Based and Clinical Data
DOI:
https://doi.org/10.65718/inspireAI.2026.1004Keywords:
Diabetes Prediction, Gradient Boosting, Machine Learning, NHANES, Plasma Glucose LevelsAbstract
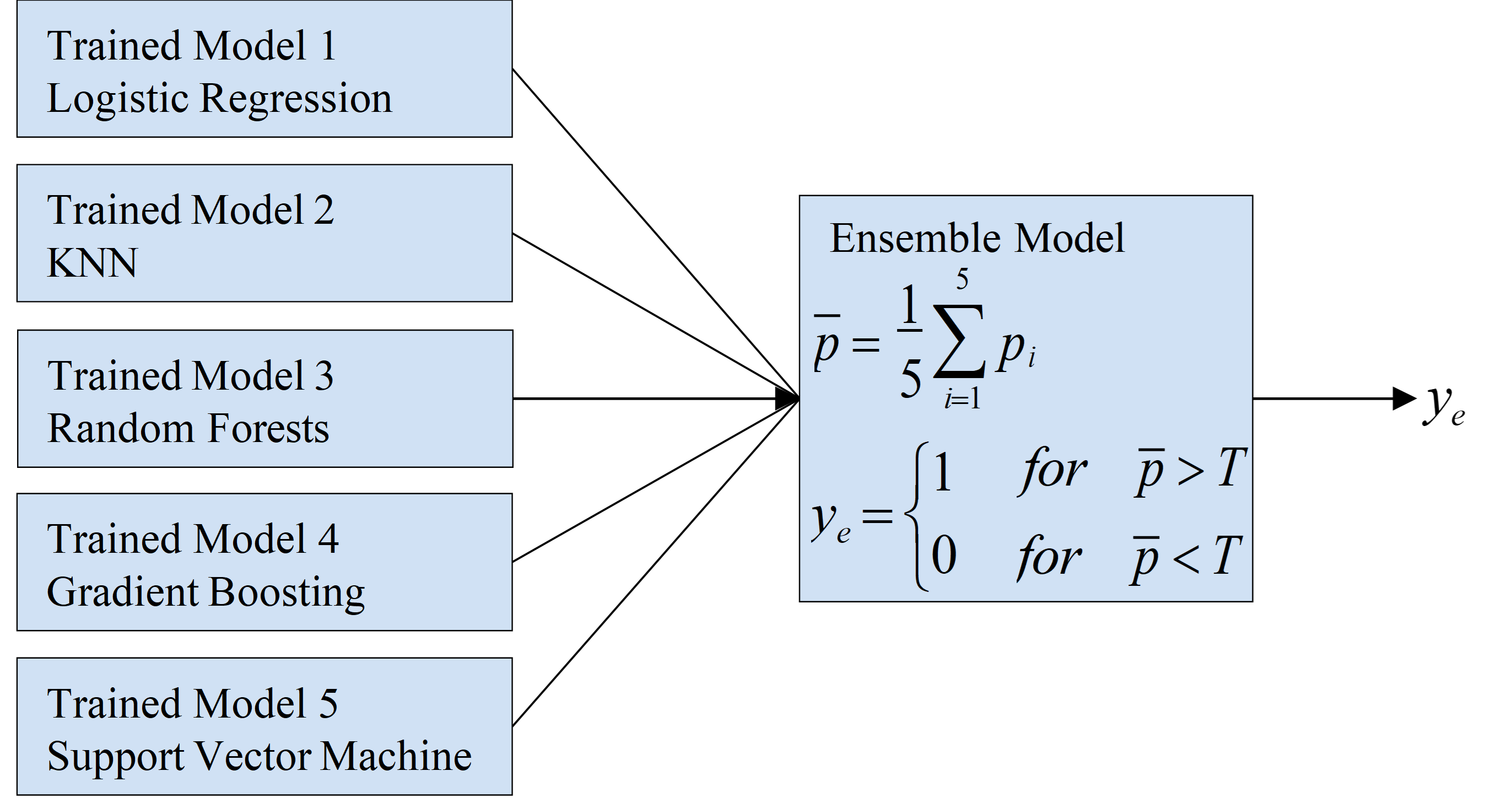
Machine learning (ML) has emerged as a significant asset in bioinformatics, particularly for early disease prediction, by leveraging various data types ranging from genetic markers to survey data. This research concentrates on diabetes prediction through the application of machine learning algorithms to data sourced from the National Health and Nutrition Examination Survey (NHANES). We built a binary classification system by looking at data from more than 5,500 non-pregnant adults. This system used reported diagnoses and plasma glucose levels to assign diabetes labels. Feature selection focused on important factors like age, waist circumference, and cholesterol, which led to a more focused set of 16 features. We trained five separate machine learning models, including Logistic Regression, K-Nearest Neighbors, Random Forests, Gradient Boosting, and Support Vector Machines. Then, to make the predictions more accurate, we combined them into an ensemble model. The ensemble did not perform better than the Gradient Boosting model, which had an AUC of 0.84. However, changing the decision threshold made it easier for diabetic patients to remember things. This study shows how useful survey data can be for predictive modeling for disease detection. It also shows how this information could be used in real life for public health programs that aim to manage and prevent diabetes.
Downloads
Published
Issue
Section
Categories
License
Copyright (c) 2026 Inspire Intelligence

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.

